
Asynchronous Exceptions in Practice
January 24, 2017Asynchronous exceptions are a controversial feature of Haskell. You
can throw an exception to another thread, at any time; all you need is
its ThreadId:
throwTo :: Exception e => ThreadId -> e -> IO ()The other thread will receive the exception immediately, whatever it is doing. So you have to be ready for an asynchronous exception to fire at any point in your code. Isn’t that a scary thought?
It’s an old idea - in fact, when we originally added asynchronous exceptions to Haskell (and wrote a paper about it), it was shortly after Java had removed the equivalent feature, because it was impossible to program with.
So how do we get away with it in Haskell? I wrote a little about the
rationale in my
book. Basically it comes down to this: if we want to be able to
interrupt purely functional code, asynchronous exceptions are the only
way, because polling would be a side-effect. Therefore the remaining
problem is how to make asynchronous exceptions safe for the impure
parts of our code. Haskell provides functionality for disabling
asynchronous exceptions during critical sections (mask) and
abstractions based around it that can be used for safe resource
acquisition (bracket).
At Facebook I’ve had the opportunity to work with asynchronous exceptions in a large-scale real-world setting, and here’s what I’ve learned:
They’re really useful, particularly for catching bugs that cause excessive use of resources.
In the vast majority of our Haskell codebase we don’t need to worry about them at all. The documentation that we give to our users who write Haskell code to run on our platform doesn’t mention asynchronous exceptions.
But some parts of the code can be really hard to get right. Code in the
IOmonad dealing with multithreading or talking to foreign libraries, for example, has to care about cleaning up resources and recovering safely in the event of an asynchronous exception.
Let me take each of those points in turn and elaborate.
Where asynchronous exceptions are useful
The motivating example often used is timeouts, for example of
connections in a network service. But this example is not all that
convincing: in a network server we’re probably writing code that’s
mostly in the IO monad, we know the places where we’re blocking, and
we could use other mechanisms to implement timeouts that would be less
“dangerous” but almost as reliable as asynchronous exceptions.
In Sigma, we use asynchronous exceptions to prevent huge requests from degrading the performance of our server for other clients.
In a complex system, it’s highly likely that some requests will end up using an excessive amount of resources. Perhaps there’s a bug in the code that sometimes causes it to use a lot of CPU (or even an infinite loop), or perhaps the code fetches some data to operate on, and the data ends up being unexpectedly large. In principle we could find all these cases and fix them, but in practice, large systems can have surprising emergent behaviour and we can’t guarantee to find all the bugs outside production.
Beware Elephants
So sometimes a request turns out to be an elephant, and we have to deal with it. If we do nothing, the elephant will trample around, slowing everything down, or maxing out some resource like memory or network bandwidth, which can cause failures for other requests running on the system.

One way or another something is going to die. We would rather it was the elephant, and not the many other requests currently running on the same machine. Stopping the elephant minimises the destruction. The elephant’s owner will then fix their problem, and we’ve mitigated a bug with minimal disruption.
Our elephant gun is called Allocation Limits. The Haskell runtime
keeps track of how much memory each Haskell thread has allocated in
total, and if that total exceeds the limit we set, the thread receives
an asynchronous exception, namely AllocationLimitExceeded. The user
code running on our platform is not permitted to catch this exception,
instead the server catches it, logs some data to aid debugging, and
sends an error back to the client that initiated the request.
We’re using “memory allocated” as a proxy for “work done”. Most computation in Haskell allocates memory, so this is a more predictable measure than wall-clock time. It’s a fairly crude way to identify excessively large requests, but it works well for us.
Here’s what happened when we enabled allocation limits early on during Sigma’s development. The graph tracks the maximum amount of live memory across different groups of machines. It turns out there were a very small fraction of requests consuming a huge amount of resources, and enabling allocation limits squashed them nicely:
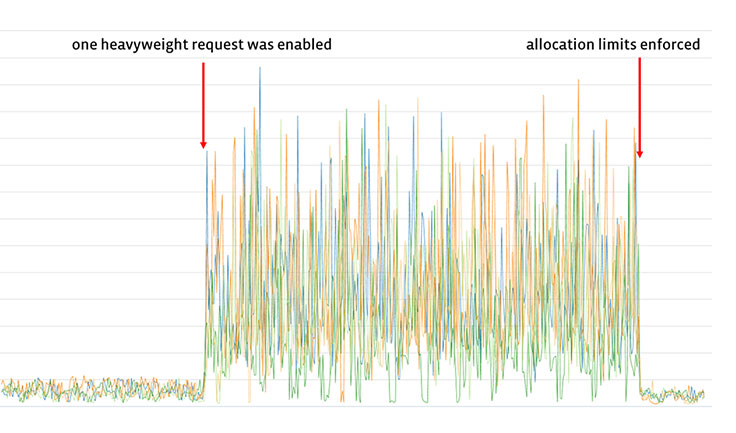
Allocation limits have helped protect us from disaster on several occasions. One time, an infinite loop made its way into production; the result was that our monitoring showed an increase in requests hitting the allocation limit. The data being logged allowed it to be narrowed down to one particular type of request, we were quickly able to identify the change that caused the problem, undo it, and notify the owner. Nobody else noticed.
In the vast majority of code, we don’t need to worry about asynchronous exceptions
Because you don’t have to poll for an asynchronous exception, they work almost everywhere. All pure code works with asynchronous exceptions without change.
In our platform, clients write code on top of the Haxl framework in which I/O is provided only via a fixed set of APIs that we control, so we can guarantee that those APIs are safe, and therefore all of the client code is safe by virtue of abstraction.
Some parts of the code can be really hard to get right
That leaves the parts of the code that implement the I/O libraries and other lower level functionality. These are the places where we have to care about asynchronous exceptions: if an async exception fires when we have just opened a connection to a remote server, we have to close it again and free all the resources associated with the connection, for example.
In principle, you can follow a few guidelines to be safe.
Use
bracketwhen allocating any kind of resource that needs to be explicitly released. This is not specific to asynchronous exceptions: coping with ordinary synchronous exceptions requires a good resource-allocation discipline, so your code should be usingbracketanyway.Use the
asyncpackage which avoids some of the common problems, such as making sure that you fork a thread insidemaskto avoid asynchronous exceptions leaking.
Nevertheless it’s still possible to go wrong. Here are some ways:
If you want asynchronous exceptions to work, be careful you don’t accidentally run inside
mask, oruninterruptibleMask. We’ve seen examples of third-party libraries that run callbacks insidemask(e.g. thehinotifylibrary until recently). UsegetMaskingStateto assert that you’re not masked when you don’t want to be.Be careful that those asynchronous exceptions don’t escape from a thread if the thread is created by calling a
foreign export, because uncaught exceptions will terminate the whole process. Unlike when usingasync, aforeign exportcan’t be created insidemask. (this is something that should be fixed in GHC, really).Catching all exceptions seems like a good idea when you want to be bullet-proof, but if you catch and discard the
ThreadKilledexception it becomes really hard to actually kill that thread.If you’re coordinating with some foreign code and the Haskell code gets an asynchronous exception, make sure that the foreign code will also clean up properly.
The type system is of no help at all with finding these bugs, the only way you can find them is with careful eyeballs, good abstractions, lots of testing, and plenty of assertions.
It’s worth it
My claim is, even though some of the low-level code can be hard to get right, the benefits are worth it.
Asynchronous exceptions generalise several exceptional conditions that relate to resource consumption: stack overflow, timeouts, allocation limits, and heap overflow exceptions. We only have to make our code asynchronous-exception-safe once, and it’ll work with all these different kinds of errors. What’s more, being able to terminate threads with confidence that they will clean up promptly and exit is really useful. (It would be nice to do a comparison with Erlang here, but not having written a lot of this kind of code in Erlang I can’t speak with any authority.)
In a high-volume network service, having a guarantee that a class of runaway requests will be caught and killed off can help reliability, and give you breathing room when things go wrong.